When and Why Previous Proxy-Reward-Based Methods Fail?
Consider the following basketball task. If we (a) only instruct the agent to learn the expert's early behaviors (reaching for and grasping the ball), the agent quickly acquires these skills. However, when (b) tasked with learning the entire expert demonstration, the same method fails to acquire the initial grasping skill, and instead, moves the empty gripper directly to the basket. This is an intriguing finding: rewarding later steps in a trajectory seems to negatively impact the agent’s ability to learn the earlier behaviors.
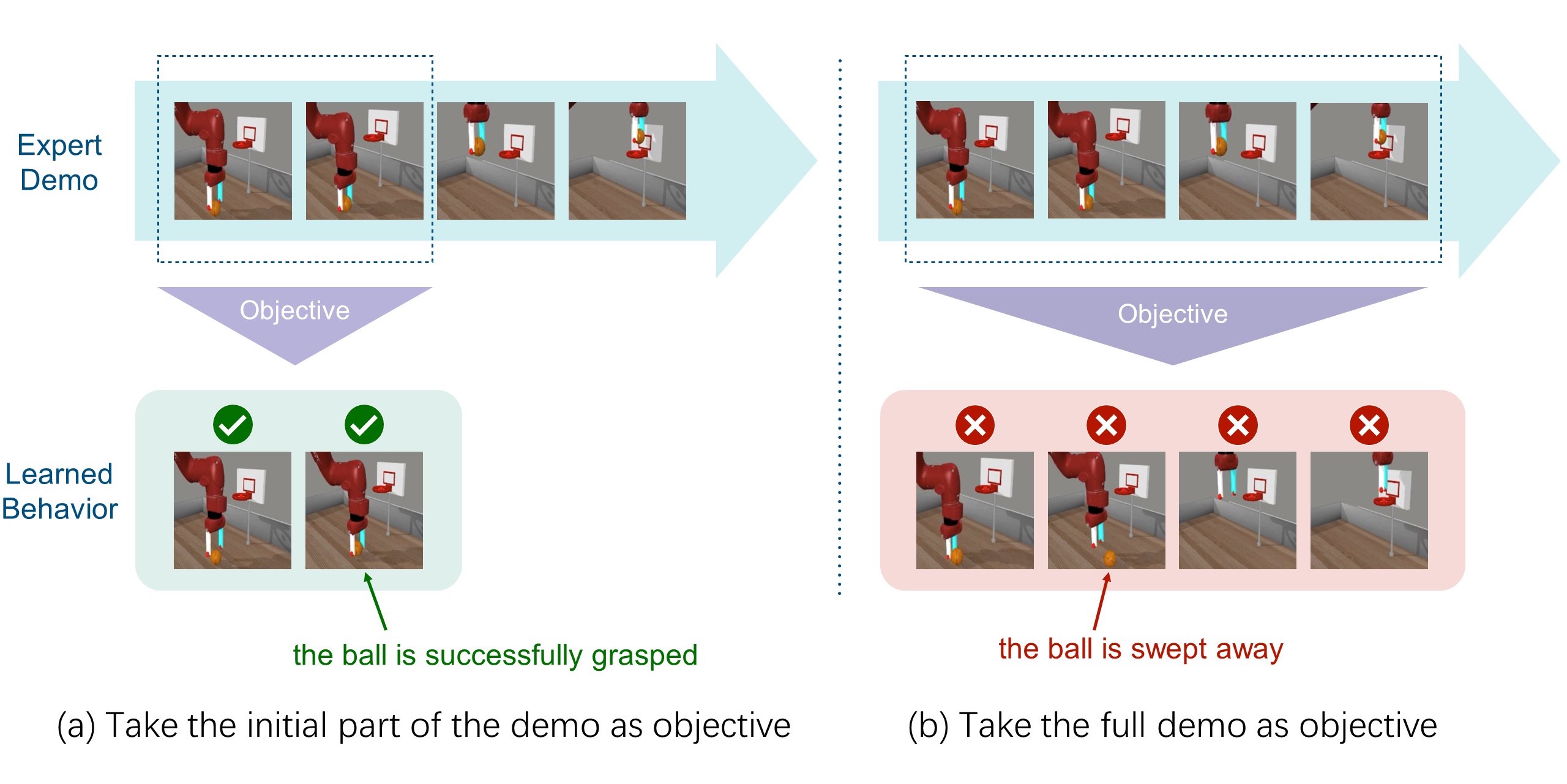
We observe a similar phenomenon in many manipulation tasks characterized by progress dependencies. In these tasks, the agents trained by previous proxy-reward-based approaches often fail to mimic the expert's early behaviors, and resort to optimizing rewards in later stages by moving to states that appear similar to demonstrated states. These locally optimal but incorrect solutions can hinder the agent's exploration of earlier critical behaviors.
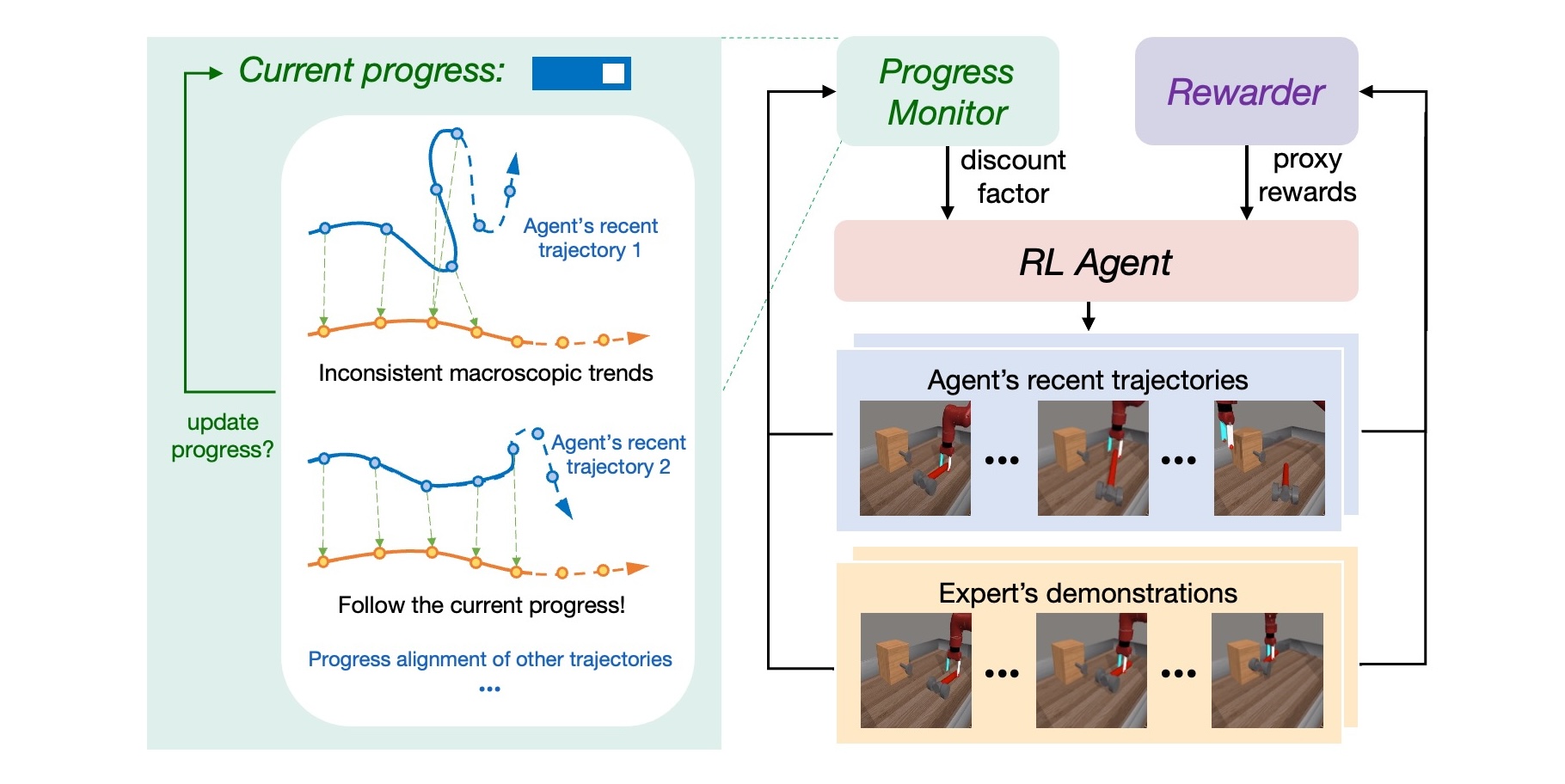
Solution: Automatic Discount Scheduling (ADS)
To address the above issue, we propose encouraging the agent to master earlier parts of demonstrated behaviors before proceeding to subsequent ones. Our method incorporates a dynamic scheduling mechanism for the discount factor: start with a relatively small discount factor to prioritize the imitation of early episode behaviors; as the agent advances in the task, the discount factor increases adaptively, allowing the agent to tackle later stages only after it has effectively learned the earlier behaviors.
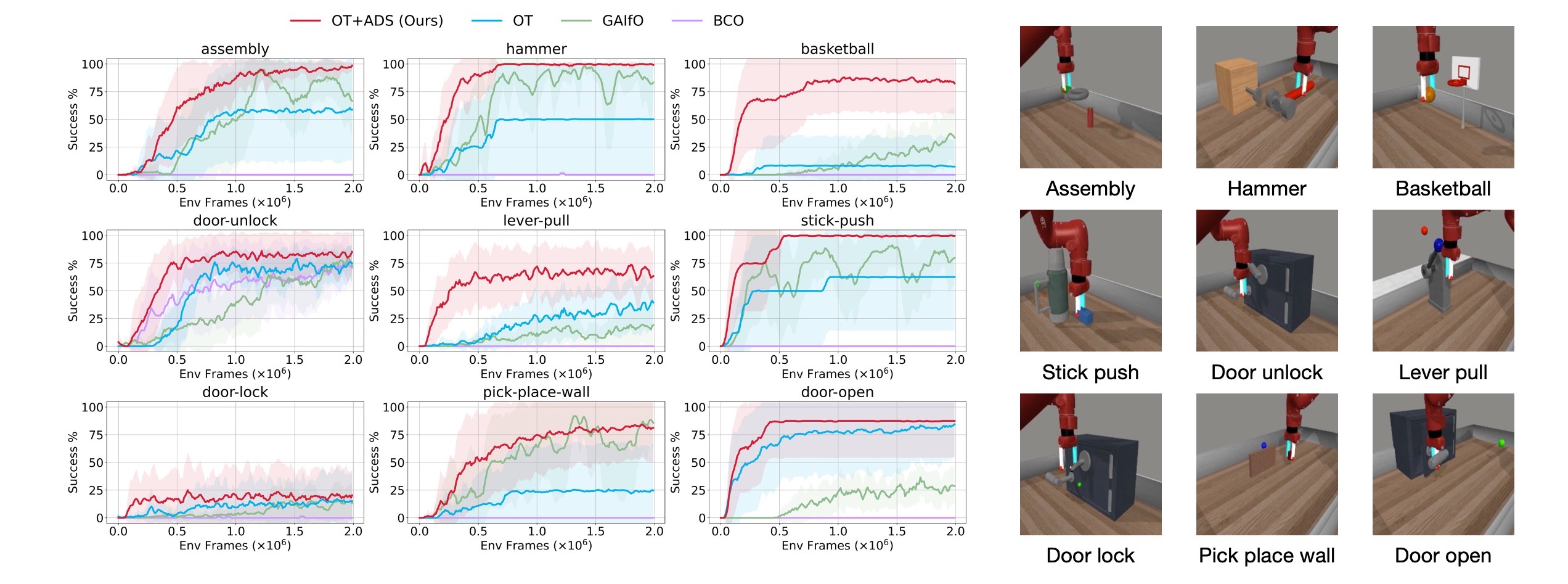
Experiment Results
Comparison against start-of-the-art ILfO baselines on 9 challenging Meta-World tasks, with 8 random seeds.
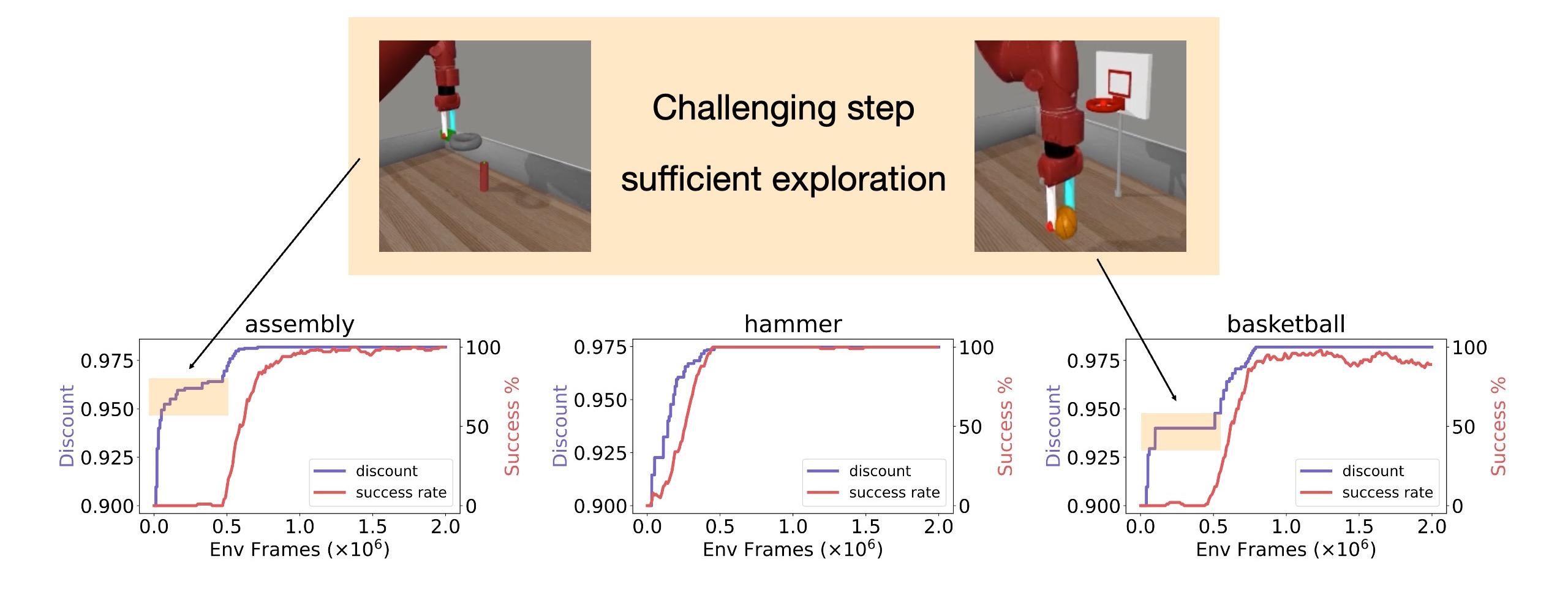
Here is the visualization of the discount factor scheduled during the training process of different tasks.
Citation
@inproceedings{
liu2024imitation,
title={Imitation Learning from Observation with Automatic Discount Scheduling},
author={Yuyang Liu and Weijun Dong and Yingdong Hu and Chuan Wen and Zhao-Heng Yin and Chongjie Zhang and Yang Gao},
booktitle={The Twelfth International Conference on Learning Representations},
year={2024},
url={https://openreview.net/forum?id=pPJTQYOpNI}
}